Functional Programming anti-patterns in Scala

Vlad Kopaniev
20 March 2023
Neil Gaiman
Google can bring you back 100,000 answers. A librarian can bring you back the right one.
This statement still holds in the new era of AI-driven assistants like ChatGPT. However convenient they might be, AI assistants still need to catch up on a lot of information and context when it comes down to explaining more complex topics like best practices of functional programming. For example, let’s look at what ChatGPT says about the “list of code smells and anti-patterns of Scala cats and cats-effect library usage.”
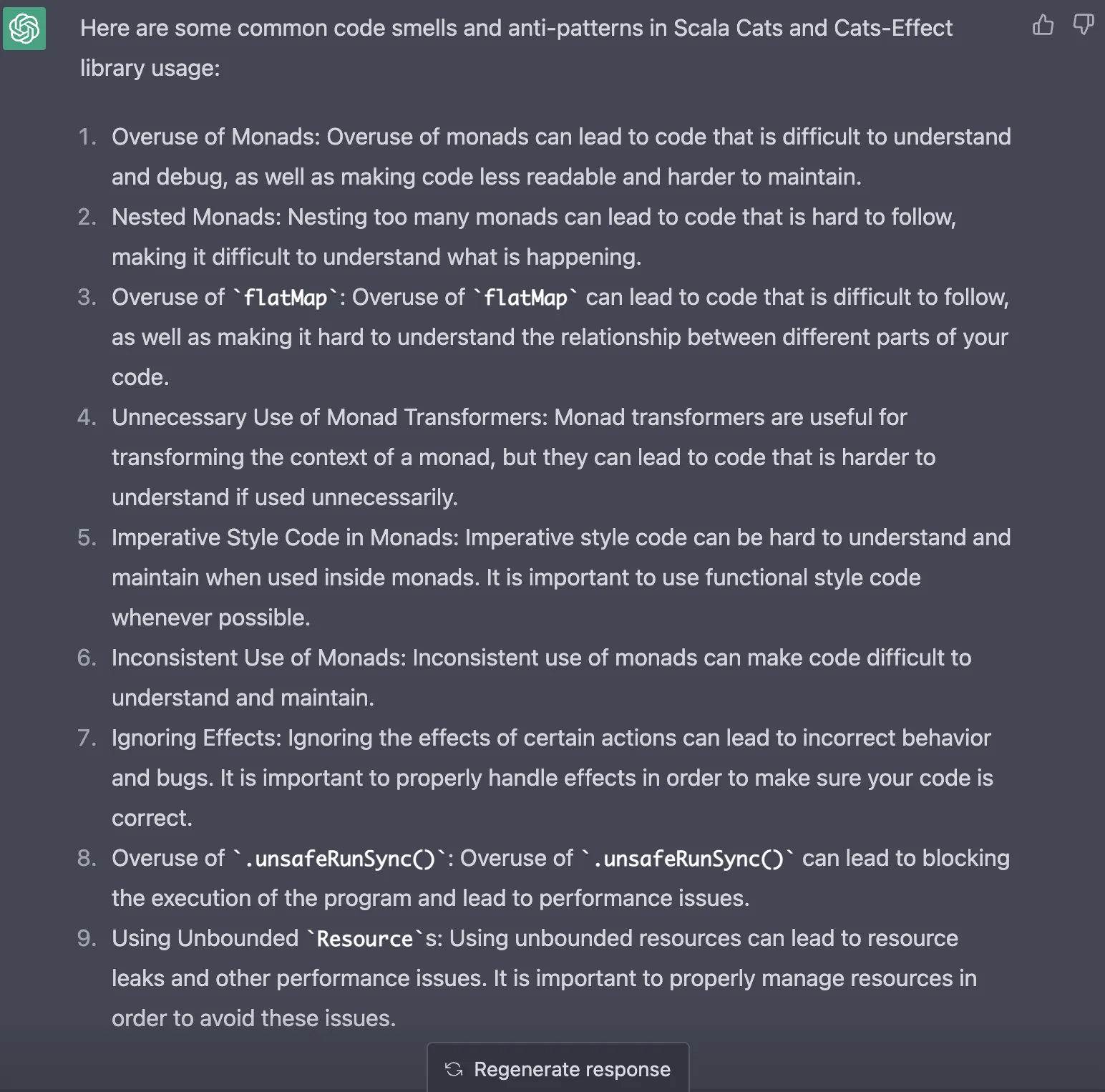
As you can see, although it has a point, most of the statements here are generic at best, and some of them are just silly. I tried other prompts, but all the answers needed more insight and gave wrong code examples. I do not recommend using ChatGPT for cases like that because it might be misleading and give you completely wrong intuition.
To be able to draw more concrete examples of best practices, you need more than AI can give you (yet). An experienced mentor who has a lot more of the context. Or an article like this that maybe the next versions of AI assistant will index and pick up for its answers))
FP anti-patterns in Scala
All right, enough of ChatGPT. Let’s get to the main topic of our discussion.
In this article, I want to help you avoid common mistakes when using FP libraries in Scala and develop some intuition into properly using it. FP is a powerful concept used to write code safely, in an easily testable and refactorable manner. However, it still can result in code smells and anti-patterns. In this article, we will discuss common code smells and anti-patterns that can arise when using FP in Scala. We will also focus on misusing the cats-effect library and provide guidance on how to avoid common mistakes.
Let’s start with common anti-patterns not specific to using cats-effect or any other FP library.
Using weakly-typed values (aka Primitive Obsession)
We will start with an anti-pattern that is highly discouraged in the functional programming community — weakly-typed values.
By “weakly-typed”, we usually mean values of types like String, Int, Long, Boolean, UUID, and so on, i.e. types that are not concerned with their real meaning for our program, be it ids, names, various settings, flags, etc. And while it is perfectly fine to use such simple types in the local scope, it might cause trouble when used across public methods and models.
Let’s see an example of using weakly-typed values in the case class that models audio settings.
case class Audio(
audioSamplingFrequency: Value,
audioBitDepth: Int,
audioCodecParameters: String,
audioTrackLayout: String,
primaryAudioLanguage: String,
secondaryAudioLanguage: String,
tertiaryAudioLanguage: String,
audioLoudnessStandard: String
)Code equivalent to this could be frequently seen written with other mainstream programming languages. But there is a problem (that Scala solves). The problem introduced with weak types is how easy it is to mix up parameters of the same type when using such APIs on the client side.
Now, you can imagine how one can write audioCodecParameters where the audioTrackLayout parameter is required and vice versa when creating an instance of this class. It becomes a real pain when dealing with 10+ parameter classes or methods.
Scala has several techniques to overcome this issue, first is to use named arguments and/or type aliases, which will make it harder to mix parameters up, but it still won’t prevent you from doing that. A preferred way is to introduce new types to replace those “weaker” types. I will not go deep into introducing the concept, but let’s say it’s like a type alias that looks different for the compiler from the original type.
With newtypes our example could change like so:
case class Audio(
audioSamplingFrequency: Frequency,
audioBitDepth: BitDepth,
audioCodecParameters: List[CodecParam],
audioTrackLayout: TrackLayout,
primaryAudioLanguage: PrimaryLanguage,
secondaryAudioLanguage: SecondaryLanguage,
tertiaryAudioLanguage: TertiaryLanguage,
audioLoudnessStandard: LoudnessStandart
)With such a declaration, using libraries like scala-newtype or monix/newtypes the compiler will generate an error if you attempt to mix up different types. This requires a bit more ceremony of defining and building these values of new types, but in exchange, you get advanced type safety, and, as a bonus, your code base becomes easier to read because strong types form a self-documenting code.
Other techniques in Scala exist that allow you to do the same things, for example, AnyVal, opaque type aliases (Scala 3), and tagged types. All of them have their strength and weaknesses compared to newtypes, you should choose based on your project needs.
Using newtypes or value types also perfectly fits into the DDD approach as it has the similar concept. Additionally, if you like to get even more typesafe consider reading PFP book, it explains the same topic and talks about typelevel validations.
The next anti-pattern is related to using weakly-typed values, but it is about a specific case of functions.
Passing dependencies as functions
object OrderService {
def apply (
userService: UserService,
discountForPoruduct: ProductId =>
OptionT[I0, DiscountResponse],
bonusForPurchase: (Int) => OptionT[I0, BonUsResponse],
productIdIsValid:
ProductId => I0[Boolean],
inStock: ProductId => I0 [Boolean]
): OrderService
}This approach might look like an idiomatic FP, because what is FP about if not about passing functions here and there, right? Wrong, passing dependencies as functions with no specific trait kills code navigation for other developers. With this approach, you can not jump to the definition of that function because it can be anywhere, and you need to first search for usages of the apply function and, from there, search for definitions. In my experience, this is not very pleasant.
Instead, try to introduce a trait or a class for such dependencies. This way, the code stays navigatable. Also, limit the creation of your HOF (Higher Order Function)s to library-like code, it might not be very clear in the land of production code.
object OrderService {
def make (
userService: UserService,
discountForProuduct: DiscountService,
bonusForPurchase: BonusesService,
productIdIsValid: ProductService
): OrderService
}Omitting return types of the public methods
Specifying return types for public methods is especially important in the library code, even more so in FP code, where sometimes types get weird if not explicitly defined.
trait HttpClientBuilder[F[_]] {
def withHostAndPort (hostname: String, port: Int) =
new HttpClientImpl(this, hostname, port)
def withBaseUrl (baseUrl: String) =
new HttpClientImpl(this, baseUrl)
}Depending on the context, this definition of trait members can give different return types! This can easily break backward compatibility when changing methods implementations or even when changing Scala versions. It is quite dangerous, so please, always specify return types of the public methods.
Now let’s focus on more specific cases related to the cats-effect library.
Using monad transformers in public API methods
trait CatalogueClient {
def lookupProduct (productId: ProductId): OptionT[IO, Product]
def addNewProduct (productId: Product):
EitherT[IO, CatalogueError, Success]
}Using monad transformers in public APIs is considered bad practice because they are hard to compose on the client side. They also could lure the client-side code into lifting their values into the monad transformer to compose them, which could be contagious and lead to noisy code base heavily polluted with things like OptionT.liftF or .value.
Instead, it’s better to return stacked monads in their simple form, i.e. IO[Option[Value]].
Suspending blocking operations
I0(s3.deleteObject (bucketName, key))Suspending blocking calls will make a thread from the common IO thread pool block until the call is not resolved. This might lead to thread starvation if too many blocking calls are executed simultaneously. This could be avoided either by using a non-blocking asynchronous version of the API (preferred) or, if there is no such API, wrapping an existing blocking call into IO.blocking or IO.interruptible/interruptibleMany depending on the ability of blocking code cancellation.
To get more deep insights into how IO works in multiple threaded environments, I highly recommend you to read the thread model page of the official cats-effect documentation.
Suspending of pure code
I0 (
AmazonSQSClientBuilder.standard
.withRegion (Regions.EU_WEST_1)
.build()
)This type of error occurs frequently and has little impact on the application. It might even happen accidentally. Still, it gives the IO runtime the wrong idea about what kind of effects you are attempting to express, which may prevent the runtime from applying the appropriate optimizations. Be cautious and wrap non-side-effecting code into IO.pure.
Note: this might be reasonable though to wrap the code that looks like pure, but you don’t know how it works, common example — Java APIs, they might throw or even make network calls inside object constructors 😬.
Leaving IO values unused
clientResource
.use { client =>
logger.info("Persisting new job: $job") //this is where you forget that you have an effectfull logger and lose the logging statement
for {
<- checkJobDoesNotExist(job.id)
<- dao.put(job)
obtained <- dao.get(job.id)
} yield obtained
}It’s not the code smell or anti-pattern per se but rather a gotcha.
This could easily happen even to experienced folks; frankly, it happened to me a couple of times too. When writing some complex logic, losing track of code flow and leaving an IO expression unused and not composed with the bigger piece is easy. For this not to happen, I recommend enabling a compiler option that reports unused values (-Wvalue-discard, -Wnonunit-statement);
Reimplementing traverse
gallery
.photoIds
.map { photoId =>
S3.objectExists(s3Client)(BucketName)(s"gallery/$userId/$photoId")
}
.sequenceThis one is very frequent. People got used to thinking they needed to map the collection into IO values first and then gather the results into one IO using sequence. In some extreme cases, people implement their own traversing functions with foldLeft, which could be a good exercise for the interview preparation, but we don’t want to reinvent the wheel in our production code, right? The same thing could be done in one step by using a traverse. You could think of traverse as an effectful forEach. So the right version would look not only simpler but also more optimized; it will make a single pass through the collection:
gallery
.photoIds
.traverse { photold =>
S3.objectExists(s3Client)(BucketName)(s"gallery/$userId/$photoId")
}Using unsafeRunSync
Sometimes developers call unsafeRunSync in the middle of the program where IO is not used for one reason or another, while other parts of the codebase successfully compose IO values. Using unsafeRunSync in most cases is bad because it breaks referential transparency, which makes reasoning about FP code obsolete. Another immediate problem that you get is having to pass an implicit runtime around or having to import the global runtime that is harder to track, all of this in order to execute the unsafeRunSync. Finally, with this function you are basically blocking the thread and that might even lead to thread starvation in your application.
The whole reason for using IO is to suspend side-effecting code to run it later in a safe manner. Suspended code can be easily composed, tested, refactored, reviewed and reasoned about.
Use unsafeRunSync only when you know exactly why you need it. Even when you make a call to IO in the unsafe environment you can use a cats-effect dispatcher to do it safely.
General advice
Bear in mind that FP code with IO, ZIO, etc, is built by defining and composing lazy values that do nothing in the place where you constructed them, this code is run later in a safe manner by a library runtime.
Another thing that people new to FP sometimes miss is that there is no sense in wrapping (or it’s better to say lifting) everything into the monad. Sometimes you could do perfectly without using IO , e.g. if your code is mostly pure. I recommend not using IO in code that does not need suspension.
Strongly consider using linter tooling like scalafix (with some custom rules for cats, e.g. xuwei-k rules), scapegoat, etc, on your project. Enable this recommended list of scala compiler flags in your sbt project, this will help you automatically detect some of the code smells discussed in this article.
Also, if you are using pre-Scala3 consider bm4 plugin to improve how for-comprehension works.
Summary
In this article we discussed common code smells and anti-patterns that arise when using functional programming libraries in Scala. We’ve seen how to avoid common mistakes and then focused on the cats-effect specific cases. We showcased such common anti-patterns as using weakly-typed values, omitting return types of public methods, and passing dependencies as functions. When it comes to using cats-effect library we say that it is best to avoid using monad transformers in public API methods, simply suspending blocking operations, suspending pure code and ignoring the traverse. We also learned that we can configure tooling to help us automatically detect and warn us about these smells.
Learning all these things on your own just from experience might be hard, so I recommend reading cats-effect docs, they are really good. Additionally, what helped me to gain this knowledge was reading books such as those mentioned below in the Links section.
Links:
- Scala Ukraine Knowledge Base — find a lot of useful and interesting material on Scala gathered by folks from the Ukrainian community.
- Practical FP In Scala by G. Volpe
- Functional Programming In Scala by M. Pilquist, R. Bjarnason, and P. Chiusano
- Domain Driven Design — Value Objects
- Scala Ukraine Telegram — channel where we discuss this and other interesting topics.
Follow Vlad on social media to stay up to date with his latest content!
- Twitter: https://twitter.com/kopaniev
- Github: https://github.com/VladKopanev